

Ich habe ja schon hin- und wieder darüber berichtet, das wir jede Nacht eine 32bit und eine 64bit Version der Baustatik auf Basis des aktuellen Entwicklungsstandes herstellen, und dann mit diesen Programmversionen eine Vielzahl an Dateien komplett durchrechnen – und die Ergebnisse dieser Berechnungen dann mit Referenzdaten vergleichen. Sinn der Sache ist es sicherzustellen, das eine durch die Weiterentwicklung entstandene Veränderung am Programm sich nicht auf die berechneten Ergebnisse auswirkt. Oder wenn, dann eben nur, weil das vom Entwickler auch gewünscht war.
Zur Zeit berechnen wir dabei pro Version ca. 3500 Eingabedateien (also insgesamt 7000). Und pro Datei gibt es dann natürlich noch jede Menge unterschiedlicher Ergebnissarten – und die an jeder Menge Stellen. Also zum Beispiel alle Auflagerkräfte für alle Lastfälle und Überlagerungen, aber eben auch alle Verformungen und Bemessungsergebnisse aller Faltwerkselemente in allen FE-Punkten. Mit einem Wort: Das sind echt viele Zahlen. Viele.
Und so machen wir das…
Zunächst mal haben wir 2 virtuelle Hyper-V Maschinen im Betrieb, beide mit installierter Quellcodeverwaltung und Visual Studio. Auf beiden werden abends Jobs angestoßen, und diese Jobs tun folgendes:
- Aktuellen Quellcode runterladen
- Programmversion herstellen (die eine virtuelle Maschine die 32bit Version, die andere die 64bit Version)
- Aktuelle Testdateien runterladen
- Für alle Testdateien alle möglichen Ergebnisse berechnen und protokollieren
- Alle Ergebnisse mit den Referenzergebnissen vergleichen und eventuell aufgetretene Unterschiede protokollieren
Alles was protokolliert wird landet in einer Datenbank (in Azure), und dafür wiederum haben wir eine (interne) Webseite, mit der man sich die Daten ansehen kann. Die liefert zunächst mal eine Übersicht, aus der hervorgeht, welche Version überhaupt gebaut werden konnte, wo Testläufe durchlaufen wurden, und wo Testläufe fehlschlugen:
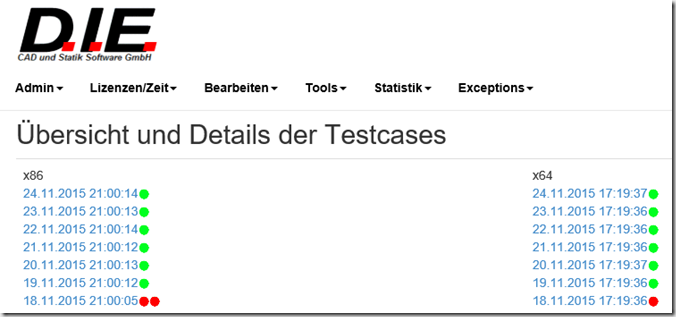
Im Fall eines Fehlschlags kann man auf den Testlauf klicken und bekommt eine Übersicht über diesen Testlauf. In dieser Übersicht sieht man dann auch schon, in welchem Bereich der Fehler lag:
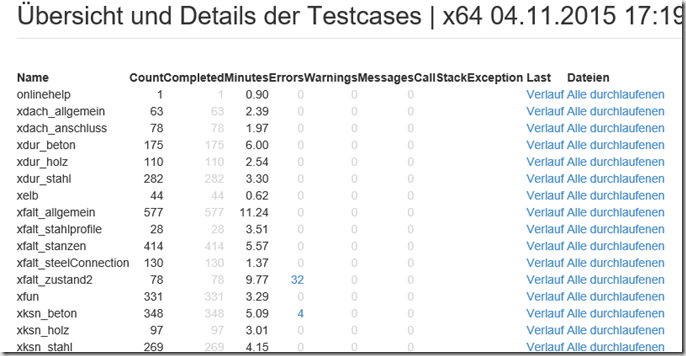
Dort kann man dann wiederum auf den Fehler klicken und bekommt alle Details dazu, was genau nicht geklappt hat:
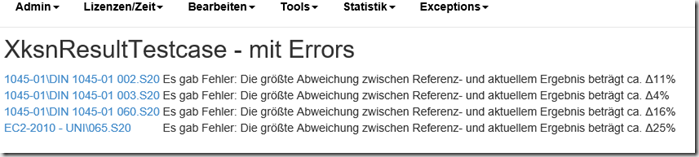
Danach kennt man also schon mal die Dokumente, bei denen es ein Problem gab und eine Zusammenfassung des Fehlers. Klickt man nun noch auf die Datei, gibt es auch (zum Teil etwas kryptische) Informationen darüber, welcher Teil der Berechnung genau nicht geklappt hat – und was genau der Fehler war:
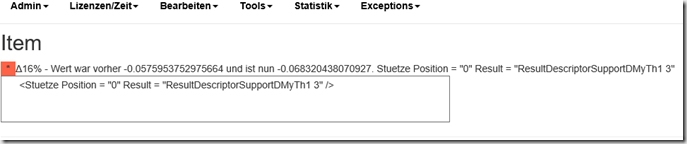
Wenn man nicht ganz so tief in die Details gehen will, dann gibt es natürlich auch etwas höher angeordnete Statistiken, zum Beispiel wie viele Testläufe durchlaufen wurden, und wie lange das gedauert hat. (Wenn sich hier was ändert, dann ist zwar nichts wirklich falsch – aber langsamer werden soll die Sache natürlich auch nicht):
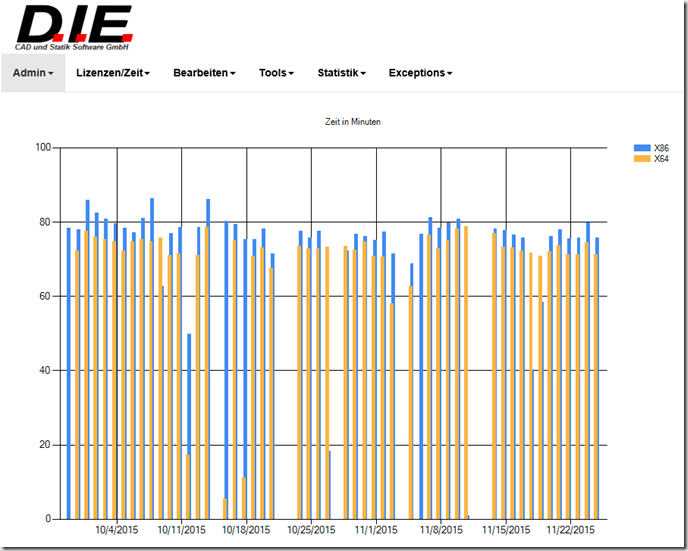
Insbesondere bei der Zeit sind kleinere Unterschiede aber zu erwarten, das bringt schon allein die Verwendung der virtuellen Maschinen mit sich: Wenn der physische Rechner in dem die sich befinden gerade etwas “interessantes” tut – also zum Beispiel ein automatisches Update einspielt – dann verändert sich die Performance der virtuellen Maschine darin – und darum kommt es zu anderen Laufzeiten. Die sollten aber immer nur gering sein – sonst stimmt mit dem Programm etwas nicht.
Und das ist im großen und ganzen die Methode, mit der wir die Übersicht über unsere Test – und das Verhalten der Baustatik – behalten: Viele, viele, viele Daten – in hübsche Graphiken verpackt. Eigentlich genau so, wie die Baustatik selbst 