

Angenommen man hat ein gescanntes Dokument oder einen Screenshot der Text enthält, und möchte nun den Text aus dem Bild in "echten" Text, also zum Beispiel in ein Word-Dokument umwandeln: Für solche Zwecke verwendet man OCR-Software, also Programme, die Text innerhalb eines Bildes erkennen und aus dem Bild extrahieren können.
Was nun viele nicht wissen: Das Microsoft Office Paket enthält (mindestens) seit der Version 2003 genau so eine Software. Und so wird die verwendet....
1.) Zunächst muss man das Werkzeug installieren, denn bei der "Standard" Installation von Office wird das Programm nicht mit installiert. Zu finden ist es im Installationsprogramm unter der Bezeichnung "Microsoft Office Document Imaging".
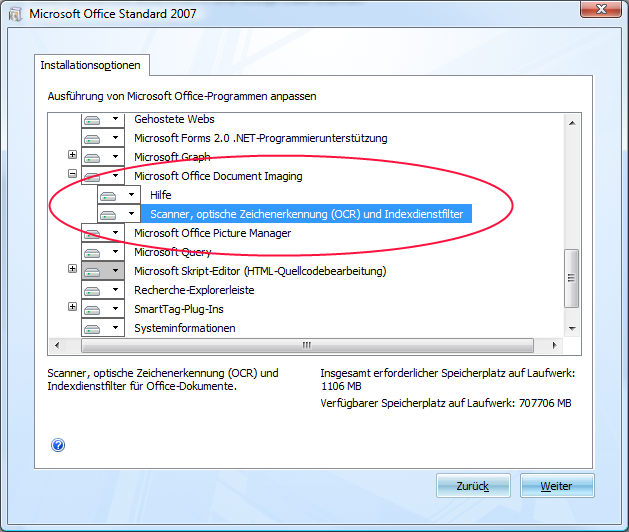
2.) Dann öffnet man das "Document Imaging" Tool. Dort kann man dann das Bild laden, das den Text enthält; als Beispiel habe ich hier einen Screenshot einer Webseite verwendet. Ist das Bild geladen, drückt man auf den Button mit dem "Auge". Das führt zu einer Untersuchung des Bildes - danach "weiss" die Software, wo sich darin Text befindet.
3.) Nun markiert man den gewünschten Text im Bild. (Das geht, weil das Programm nach dem 2. Schritt zusätzlich zu den Bilddaten auch Informationen über die Textposition darin kennt. Das sieht dann ungefährt so aus:
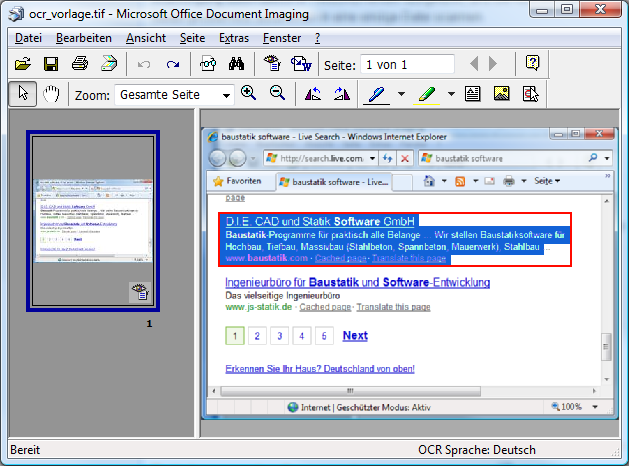
4.) Nun drückt man auf den Button mit dem Word-Symbol: Das transferiert den Text nach Word. Dort sieht die Sache auf Basis des Beispiels dann so aus:
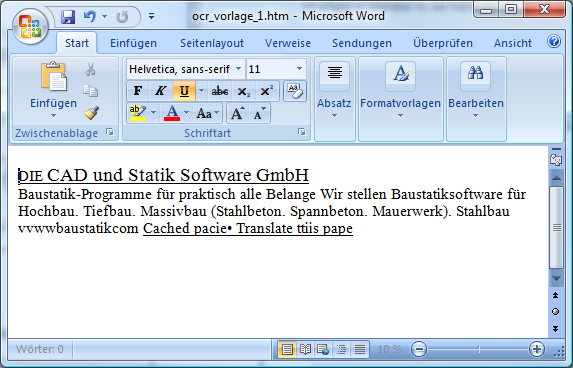
Wie man sieht gibt es zwar ein paar kleinere Fehler, der wesentliche Teil des Textes kommt aber korrekt an.